

Enterprise Information Architecture as a foundation for successful data quality management.
Abstract
Data quality is a well-known problem and a very expensive one to fix. While it has been plaguing major US corporations for quite some time, lately it is becoming increasingly painful. Higher prominence of various regulatory compliance acts, i.e., SOX, GLB, Basel II, HIPPA, HOEPA, etc necessitates an adequate response to the problem.
A common approach to data quality problem usually starts and ends with the activities scoped to the physical data storage layer (frequently relational databases) in the classes of applications that heavily depend on enterprise data quality: i.e., Business Intelligence, Finance reporting, Market Trend Analysis, etc.
Not surprisingly, according to the trade publications, most of these efforts have minimal success. Given that in business applications data always exist within the context of a business process, all the attempts to solve “data quality problem” at the pure physical data level (a.k.a. databases and ETL tools) are doomed to fail.
Successful business data management begins by taking focus away from data. The focus initially should be on creation of Enterprise Architecture, especially commonly missing Business as well as Information architectures constituents of it. Information Architecture spans Business and Technology architectures, brings them together, keeps them together and provides necessary rich contextual environment to solve the ubiquitous “data quality problem”.
Thus Enterprise Business, Information and Technology architectures are needed for successful data management.
Data Quality
Data Quality Deficiency Syndrome
Major business initiatives in a broad spectrum of industries, private and public sectors alike, have been delayed and even cancelled citing poor data quality as the main reason. The problem of poor information quality has become so severe, that it has moved to the top tier among the reasons for business customers’ dissatisfaction with their IT counterparts.
While it is hardly an argument that poor data quality is probably the most noticeable issue, in a vast majority of cases, it will be accompanied by the equally poor quality of systems engineering in general, i.e., requirements elicitation and management, application design, configuration management, change control, and overall project management. The popular belief that “if we just get data under control, the rest (usability, scalability, maintainability, modifiability, etc) will also follow”, has proven to be consistently wrong. I have never seen a company where data quality level was significantly different from the overall IT environment quality level. If business applications in general are failing to meet (even) realistic expectations of the business users, then data is just one of the reasons cited, albeit the most frequent one. As a corollary to this, if business users are happy with the level of IT services, usually all the quality parameters of the IT organization effort are at a satisfactory level. I challenge the readers, from their prior experience and knowledge, to come up with an example where data quality in a company was significantly different from the rest of the information systems quality parameters.
What is commonly called “poor data quality problem” should be more appropriately called the “data quality deficiency syndrome”. It is indeed just a symptom of a larger and more complex phenomenon that can be called something to the kind of “poor quality of systems engineering in general”. Data quality is just the most tangible and obvious problem that our business partners do observe 1.
What is data?
Since data plays such a prominent role in our discussion, let’s first agree on what data is. Generally, most agree that “data 2” is a statement accepted at face value. A large class of data is measurements of a variable.
While all the examples in this article assume numeric and alphanumeric values, the assertions should be applicable to image-typed values as well.
_______________________________________________________
1 For a great example on how an attempt to deal with data architecture separately from all the other architectural issues leads to potentially significant problems, please see the following article in the Microsoft’s Architecture Journal.
The Architecture Journal, “Data Replication as an Enterprise SOA Antipattern”, http://www.architecturejournal.net/2006/issue8/F4_Data/
2 Data is the plural of “datum”.
Data context
A notion that data is produced by measurements or observations is very significant. It points to a very important concept that is absolutely critical to the success of any data quality improvement effort. This concept is a notion of data context or metadata. In other words, a number just by itself, stripped of its context, is not really meaningful for business users. For example, the number 10 taken without an appropriate context bears little use. However, if one learns that we are talking about 10 cars and not 10 bikes, it now yields a better understanding of the business situation. The more data context is available, the better is our ability to understand what this piece of data really means. To continue with the example noted above, so far we have learned that we are talking about 10 cars. Now if we add to this context that we are talking about “10 cars waiting detailing and then delivery to a specific party, let’s say “Z Car Shop”, that has already paid for them”, we now have a much better understanding of the business circumstances surrounding this number. This is at the crux of “poor data quality problem” – lack of sufficient data context. We typically do not have enough supporting information to understand what a particular number (or a set of numbers) means, and we thus cannot make an accurate judgment about validity and applicability of the data. 3
As an IT consultant Ellen Friedman puts it: “Trying to understand the business domain by understanding individual data elements out of context is like trying to understand a community by reading the phone book.”
The class of data that is the subject of this article always exists within a context of a business process. In order to solve “poor data quality problem”, data context should always be well-defined, well-understood, and well-managed by data producers and consumers.
Data quality attributes
Professor Richard Wang of MIT, defines 15 dimensions or categories of data quality problems. They are: accuracy, objectivity, believability, reputation, relevancy, value-added, timeliness, completeness, amount of information, interpretability, ease of understanding, consistent representation, concise representation, access, and security.
A serious discussion of the above list would warrant a whole book; however, it is important to make a point that most of these attributes are in fact representing the notion of data context. For the purpose of our discussion on data quality, the most relevant attributes are: interpretability, ease of understanding, completeness, and timeliness.
The timeliness attribute also known as temporal aspect of information/data is arguably the most intricate one from the data quality perspective.
There are at least two interpretations of data timeliness. The first deals with our ability to present required data to a data consumer on time. It is a derivative of good
___________________________________________________________
3 It is necessary to acknowledge that there is a class of data problems that is rooted in technology. These are problems related to usage of wrong technology, coding mistakes, such as errors in calculations and transformations, etc. All these problems, however, are relatively easy to detect and thus fix if a rigorous development process is used. This class of data problems, while being vital in certain cases, (e.g. losing the Mars Climate Orbiter in 1998 due to a programming error) is not the subject of this article.
requirements and design, but in the context of this article, it is of little interest to us. The second aspect is the notion of data having a distinctive “time/event stamp” related to the business process, and thus allowing us to interpret data in conjunction with the appropriate business events. It is not hard to see that more than half of the data quality attributes in the list above are at least associated with, if not derived from, this interpretation of timeliness. The importance of the time/event attribute points to a fundamental problem with the conventional data modeling technique, i.e., entity-relationship modeling or entity-relationship diagram (ERD). The ERD method lacks any mechanism similar to UML’s Event and State Transition Diagrams. This gap in turn leads not only to a consistent under-representation of this extremely important aspect of data quality in the conventional data models, but also creates a serious knowledge-management problem for a large group of players in the data quality arena.
According to J.M. Juran, a well known authority in the quality control area and the author of the Pareto principle, which is commonly referred to today as the “80-20 principle”, data are of high quality "if they are fit for their intended uses in operations, decision making and planning. Alternatively, data are deemed of high quality if they correctly represent the real-world construct to which they refer.” 4
Again, this definition points to the notion that data quality is dependent on our ability to understand data correctly and use them appropriately.
As an example, consider U.S. postal address data. Postal addresses are one of the very few data areas that have well defined and universally accepted standards. Even though an address can be validated against commercially available data banks to ensure its validity, this is not enough. If a shipping address is used for billing and vice-versa, or borrower correspondence address is used for appraisal, the results obviously will be wrong.
As already discussed above, the temporal aspect of information quality is extremely important for understanding and communicating, but it is often lost. For example, in the mortgage-backed securities arena, there are two very similar processes with almost identical associated data. First is Asset Accounting Cycle, which starts at the end of the month for interest accrual due next period. The second is the Cash Flow Distribution Cycle, which starts 15 days after the Asset Accounting Cycle begins. This difference of 15 calendar days, during which many possible changes to status of a financial asset can take place, can make financial outcomes differ significantly, but from the pure data modeling perspective, the database models in both cases are very similar or even identical. A data modeler who is not intimately familiar with the nuances of a business process, will not be able to discern the difference between the data associated with disparate processes by just analyzing the data in the database.
________________________________________________________________
4 Juran, Joseph M. and A. Blanton Godfrey, Juran's Quality Handbook, Fifth Edition, p. 2.2, McGraw-Hill, 1999
Architecture
Architecture as metadata source
As previously discussed, conventional data modeling techniques do not contain a mechanism that can provide sufficiently rich metadata, which is absolutely necessary for any successful data quality improvement effort to be successful. At the same time, this rich contextual model is a natural byproduct of successful Enterprise Architecture (EA) development process so long as this process adheres to a rigorous engineering approach5.
Architecture definition
Architecture is one of the most used (and abused) terms in the areas of software and systems engineering. In order to get a good feel for the complexity of the systems architecture topics, it suffices to list some of the most commonly used architectural categories, methods and models: Enterprise, Data, Application, Systems, Infrastructure, Zachman, Information, Business, Network, Security, Model Driven Architecture (MDA) and certainly the latest silver-bullet: Service-Oriented Architecture (SOA). All of the above architecture types naturally have a whole body of theoretical and practical knowledge associated with them. Any in depth discussion about various architectural categories and approaches is clearly outside the scope of this article; however, it is important to concentrate on the concept of Enterprise Architecture, and the following definition by Philippe Kruchten provide the context for this discussion “Architecture encompasses the set of significant decisions about the system structure”6.
Similarly, Eberhardt Rechtin states7 “A system is defined ... as a set of different elements so connected or related as to perform a unique function not performable by the elements alone”.
In order to emphasize the practical side of architecture development, the two definitions above can be further enriched and a long-time colleague of mine Mike Regan a systems architect with many successful system implementations under his belt adds: “Architecture can be captured as a set of abstractions about the system that provide enough essential information to form the basis for communication, analysis, and decision making.”
From the above definitions, it is clear that system architecture is the fundamental organization of a system. System architecture contains definitions of the main system constituencies, as well as the relationships among these constituencies.
Naturally, the architecture of a complex system is very complex as well. In order to deal with such architectural complexity, some decomposition method is needed. One such method is the Three-Layered Model.
_________________________________
5 It is prudent to concentrate on Enterprise-level architecture since it is the most semantically difficult level and thus has the highest return potential for data quality improvements. All the discussion points below will be also applicable to any lower level concepts: LOB, department, etc.
6 Philippe Kruchten, http://www.kruchten.com/inside/citations/Kruchten2004_DesignDecisions.pdf
7 Systems Architecting: Creating and building complex systems, Eberhardt Rechtin, Prentice-Hall, 1991
Three-Layered Model
All modern architectural approaches are centered on a concept of model layers -- horizontally-oriented groups defined by a common relationship with other layers, usually their immediate neighbors above and below. A possible layering for EA can constitute a capabilities (or business process) layer at the top, the information technology specifications layer in the middle, and the information technology physical implementation layer on the bottom . This model assumes information systems-centered approach; in other words, the purpose of this architectural model is to provide an approach to successful information systems implementation.
A simplified Three-Layered Model is shown in Figure 1. Some key concepts are worth mentioning:
First, although business strategy is not a constituent of the Business Architecture layer, it represents a set of guidelines for enterprise actions regarding markets, products, business partners and clients. A more elaborate view of these actions is captured by Business Architecture.
Second, the model demonstrates that Enterprise Information Models reside in both the Conceptual as well as in the Logical layers, and provide the foundation for consistent interaction between these layers.
Third, Enterprise IT Governance Framework is defined in the top conceptual layer, while IT standards and guidelines that support the Governance Framework are implemented in the Specification layer.
Finally, Enterprise Specification Layer defines only Enterprise Integration Model for the departmental systems, but not their internal architectures.
The discussion that succeeds the diagram expands on the notion of business process architecture and elaborates on the layering details.
_____________________________________________________
8 This approach is inspired by Martin Fowler’s book “Analysis Patterns: Reusable Object Models”, http://www.martinfowler.com/books.html#ap, as well as by OMG’s Model Driven Architecture (MDA) http://www.omg.org/mda/

Business Architecture
It is important to emphasize the business process layer as the foundation for our Enterprise Architecture model. Carnegie Mellon University (CMU) provides the following definition for Enterprise Architecture: “A means for describing business structures and processes that connect business structures”. Interestingly enough this definition from the CMU Software Architecture Glossary is actually applicable to and definitive of the EA as a whole, and not just for the Business EA.
EA definition used by the US Government agencies and departments emphasizes a strategic set of assets, which defines the business, as well as the information necessary to operate the business, and the technologies necessary to support the business operations.
While this definition maps extremely well to the above proposed three layered view of EA, a word of caution is appropriate: while three layered model provides a good first approximation of Enterprise Architecture, it is by no means complete and/or rigorous. It is obvious that both business and technical constituencies of the EA model can and should be in turn decomposed into multiple sub-layers.
In the quest to make Business Enterprise Architecture (BEA) layer a robust practical concept, BEA has morphed from the initial organizational chart-centered and thus brittle view, into a business process-centered orientation, and lately into business capabilities-centered view, becoming even more resilient to business changes and transformations .
Current consensus around EA accentuates both business and technical constituencies of it. This business and IT partnership is even more highlighted by the advances of the service-oriented architecture (SOA), which views businesses process model and supporting technology model as an assembly of inter-connected services.
__________________________________________________
9 CMU SEI, Software Architecture Glossary, http://www.sei.cmu.edu/architecture/glossary.html
10 http://colab.cim3.net/cgi-bin/wiki.pl?Enterprise_Architecture
The original version is: “Enterprise Architecture ‘‘(A) means—‘‘(i) a strategic information asset base, which defines the mission; ‘‘(ii) the information necessary to perform the mission; ‘‘(iii) the technologies necessary to perform the mission; and ‘‘(iv) the transitional processes for implementing new technologies in response to changing mission needs; and ‘‘(B) includes—‘‘(i) a baseline architecture; ‘‘(ii) a target architecture; and ‘‘(iii) a sequencing plan…”
11 A Business-Oriented Foundation for Service Orientation, Ulrich Homann http://msdn.microsoft.com/architecture/default.aspx?pull=/library/en-us/dnbda/html/ServOrient.asp
Architectural model as a foundation for data quality improvement
Top Business layer
In the proposed three-layered view of the EA, the business process (or capabilities) layer includes a business domain class model . Since this model is implemented at the highest possible level of abstraction, it captures only foundational business entities and their relationships. Thus, the top layer domain model is very stable and is not subject to change unless the most essential underlying business structures change. The information (or data) elements that are defined at this level of the domain model are cross-referenced against the business process model residing in the same top layer. In other words, every domain model element has at least one business process definitions that references it. The reverse is also true: there is no information element called out in the business processes definitions that does not exist in the domain model.
It is also worth pointing out that only common enterprise-level information processes and elements are captured at the top layer of EA. For example, due to historical reasons, an enterprise consists of multiple lines of business (LOB), each carrying out its own unique business process with related information definitions. At the same time, all the LOBs participate in the common enterprise process. In this case, at the top (enterprise level) business process layer, only the common enterprise-level process will be modeled. In extreme cases, this enterprise process will primarily consist of the interfaces between the LOB-level business processes.
Each of the enterprise’s LOBs will need to have its own three-layered model, where top level business entities and the corresponding information (or data) elements will be unambiguously mapped to the enterprise-level model entities. Needless to say, only the elements that have their counterparts at the enterprise level can possibly be mapped. By relating LOB-level definitions to the common enterprise-level equivalents, we are eliminating one of the main reasons for low enterprise data quality: semantic mismatch (a.k.a. ambiguity) between different business units. And since our data elements are cross-referenced with the business process models, we should have enough contextual information to correlate information elements at the enterprise- and LOB- levels. In the most difficult cases, UML State Transition Diagrams should be created to capture temporal and event aspects of the business processes.
Specification layer
The Specification Layer of the three-layered EA model introduces system-related considerations and defines specifications for the enterprise-level information systems. These are the systems that need to be constructed to support the business processes defined at the top layer of the model. By defining system requirements in terms of the business processes, another major cause of low data quality is eliminated: a disconnect between the business and the technology views of the enterprise system.
For example, it is quite common for more than one system to be operating on a data element defined at the top business layer. In this case, each system specification will define its own unique data attribute, but all these attributes are in turn mapped to the one element at the top layer. This top down decomposition approach helps to alleviate a problem known as “departmental information silo”.
Again, similar to the top layer, in the spirit of correlating data with the process contextual information, Business Use Cases Realizations and System Use Cases (or similar artifacts) are introduced at this level to provide enough grounding for the data definitions. It is important to note that in addition to the enterprise systems, the system interfaces of LOB-level systems (to support business process connection points between the different LOBs) are also specified in this layer.
Implementation layer
In this layer, the platform-specific implementation are defined and implemented. Unlike at the Specification layer, multiple platform specific implementations may be mapped to the same element defined at the specification layer. This unambiguous, contextually-based mapping from possibly multiple technology-specific implementations to a data element defined at the technology-independent specification level is the foundation for the robust high quality data management approach.
Conclusion
It is impossible to overestimate the importance of the two-dimensional traceability in the discussed architectural model. The first dimension – vertical traceability between the model layers – provides a foundation for rich contextual connection between the business process and the system implementation that supports this process. The second dimension – horizontal traceability within the same model layer – provides a foundation for a rich contextual connection between the hierarchical organizational units, as well as the systems implemented at their respective levels.
A robust traceability mechanism is absolutely necessary for high data quality to become a reality. The architectural model provides a foundation for the information traceability and thus data quality, without which it is not possible to address a cluster of issues introduced by the modern business environment in general and especially by the legal and regulatory compliance concerns.
Abstract
Data quality is a well-known problem and a very expensive one to fix. While it has been plaguing major US corporations for quite some time, lately it is becoming increasingly painful. Higher prominence of various regulatory compliance acts, i.e., SOX, GLB, Basel II, HIPPA, HOEPA, etc necessitates an adequate response to the problem.
A common approach to data quality problem usually starts and ends with the activities scoped to the physical data storage layer (frequently relational databases) in the classes of applications that heavily depend on enterprise data quality: i.e., Business Intelligence, Finance reporting, Market Trend Analysis, etc.
Not surprisingly, according to the trade publications, most of these efforts have minimal success. Given that in business applications data always exist within the context of a business process, all the attempts to solve “data quality problem” at the pure physical data level (a.k.a. databases and ETL tools) are doomed to fail.
Successful business data management begins by taking focus away from data. The focus initially should be on creation of Enterprise Architecture, especially commonly missing Business as well as Information architectures constituents of it. Information Architecture spans Business and Technology architectures, brings them together, keeps them together and provides necessary rich contextual environment to solve the ubiquitous “data quality problem”.
Thus Enterprise Business, Information and Technology architectures are needed for successful data management.
Data Quality
Data Quality Deficiency Syndrome
Major business initiatives in a broad spectrum of industries, private and public sectors alike, have been delayed and even cancelled citing poor data quality as the main reason. The problem of poor information quality has become so severe, that it has moved to the top tier among the reasons for business customers’ dissatisfaction with their IT counterparts.
While it is hardly an argument that poor data quality is probably the most noticeable issue, in a vast majority of cases, it will be accompanied by the equally poor quality of systems engineering in general, i.e., requirements elicitation and management, application design, configuration management, change control, and overall project management. The popular belief that “if we just get data under control, the rest (usability, scalability, maintainability, modifiability, etc) will also follow”, has proven to be consistently wrong. I have never seen a company where data quality level was significantly different from the overall IT environment quality level. If business applications in general are failing to meet (even) realistic expectations of the business users, then data is just one of the reasons cited, albeit the most frequent one. As a corollary to this, if business users are happy with the level of IT services, usually all the quality parameters of the IT organization effort are at a satisfactory level. I challenge the readers, from their prior experience and knowledge, to come up with an example where data quality in a company was significantly different from the rest of the information systems quality parameters.
What is commonly called “poor data quality problem” should be more appropriately called the “data quality deficiency syndrome”. It is indeed just a symptom of a larger and more complex phenomenon that can be called something to the kind of “poor quality of systems engineering in general”. Data quality is just the most tangible and obvious problem that our business partners do observe 1.
What is data?
Since data plays such a prominent role in our discussion, let’s first agree on what data is. Generally, most agree that “data 2” is a statement accepted at face value. A large class of data is measurements of a variable.
While all the examples in this article assume numeric and alphanumeric values, the assertions should be applicable to image-typed values as well.
_______________________________________________________
1 For a great example on how an attempt to deal with data architecture separately from all the other architectural issues leads to potentially significant problems, please see the following article in the Microsoft’s Architecture Journal.
The Architecture Journal, “Data Replication as an Enterprise SOA Antipattern”, http://www.architecturejournal.net/2006/issue8/F4_Data/
2 Data is the plural of “datum”.
Data context
A notion that data is produced by measurements or observations is very significant. It points to a very important concept that is absolutely critical to the success of any data quality improvement effort. This concept is a notion of data context or metadata. In other words, a number just by itself, stripped of its context, is not really meaningful for business users. For example, the number 10 taken without an appropriate context bears little use. However, if one learns that we are talking about 10 cars and not 10 bikes, it now yields a better understanding of the business situation. The more data context is available, the better is our ability to understand what this piece of data really means. To continue with the example noted above, so far we have learned that we are talking about 10 cars. Now if we add to this context that we are talking about “10 cars waiting detailing and then delivery to a specific party, let’s say “Z Car Shop”, that has already paid for them”, we now have a much better understanding of the business circumstances surrounding this number. This is at the crux of “poor data quality problem” – lack of sufficient data context. We typically do not have enough supporting information to understand what a particular number (or a set of numbers) means, and we thus cannot make an accurate judgment about validity and applicability of the data. 3
As an IT consultant Ellen Friedman puts it: “Trying to understand the business domain by understanding individual data elements out of context is like trying to understand a community by reading the phone book.”
The class of data that is the subject of this article always exists within a context of a business process. In order to solve “poor data quality problem”, data context should always be well-defined, well-understood, and well-managed by data producers and consumers.
Data quality attributes
Professor Richard Wang of MIT, defines 15 dimensions or categories of data quality problems. They are: accuracy, objectivity, believability, reputation, relevancy, value-added, timeliness, completeness, amount of information, interpretability, ease of understanding, consistent representation, concise representation, access, and security.
A serious discussion of the above list would warrant a whole book; however, it is important to make a point that most of these attributes are in fact representing the notion of data context. For the purpose of our discussion on data quality, the most relevant attributes are: interpretability, ease of understanding, completeness, and timeliness.
The timeliness attribute also known as temporal aspect of information/data is arguably the most intricate one from the data quality perspective.
There are at least two interpretations of data timeliness. The first deals with our ability to present required data to a data consumer on time. It is a derivative of good
___________________________________________________________
3 It is necessary to acknowledge that there is a class of data problems that is rooted in technology. These are problems related to usage of wrong technology, coding mistakes, such as errors in calculations and transformations, etc. All these problems, however, are relatively easy to detect and thus fix if a rigorous development process is used. This class of data problems, while being vital in certain cases, (e.g. losing the Mars Climate Orbiter in 1998 due to a programming error) is not the subject of this article.
requirements and design, but in the context of this article, it is of little interest to us. The second aspect is the notion of data having a distinctive “time/event stamp” related to the business process, and thus allowing us to interpret data in conjunction with the appropriate business events. It is not hard to see that more than half of the data quality attributes in the list above are at least associated with, if not derived from, this interpretation of timeliness. The importance of the time/event attribute points to a fundamental problem with the conventional data modeling technique, i.e., entity-relationship modeling or entity-relationship diagram (ERD). The ERD method lacks any mechanism similar to UML’s Event and State Transition Diagrams. This gap in turn leads not only to a consistent under-representation of this extremely important aspect of data quality in the conventional data models, but also creates a serious knowledge-management problem for a large group of players in the data quality arena.
According to J.M. Juran, a well known authority in the quality control area and the author of the Pareto principle, which is commonly referred to today as the “80-20 principle”, data are of high quality "if they are fit for their intended uses in operations, decision making and planning. Alternatively, data are deemed of high quality if they correctly represent the real-world construct to which they refer.” 4
Again, this definition points to the notion that data quality is dependent on our ability to understand data correctly and use them appropriately.
As an example, consider U.S. postal address data. Postal addresses are one of the very few data areas that have well defined and universally accepted standards. Even though an address can be validated against commercially available data banks to ensure its validity, this is not enough. If a shipping address is used for billing and vice-versa, or borrower correspondence address is used for appraisal, the results obviously will be wrong.
As already discussed above, the temporal aspect of information quality is extremely important for understanding and communicating, but it is often lost. For example, in the mortgage-backed securities arena, there are two very similar processes with almost identical associated data. First is Asset Accounting Cycle, which starts at the end of the month for interest accrual due next period. The second is the Cash Flow Distribution Cycle, which starts 15 days after the Asset Accounting Cycle begins. This difference of 15 calendar days, during which many possible changes to status of a financial asset can take place, can make financial outcomes differ significantly, but from the pure data modeling perspective, the database models in both cases are very similar or even identical. A data modeler who is not intimately familiar with the nuances of a business process, will not be able to discern the difference between the data associated with disparate processes by just analyzing the data in the database.
________________________________________________________________
4 Juran, Joseph M. and A. Blanton Godfrey, Juran's Quality Handbook, Fifth Edition, p. 2.2, McGraw-Hill, 1999
Architecture
Architecture as metadata source
As previously discussed, conventional data modeling techniques do not contain a mechanism that can provide sufficiently rich metadata, which is absolutely necessary for any successful data quality improvement effort to be successful. At the same time, this rich contextual model is a natural byproduct of successful Enterprise Architecture (EA) development process so long as this process adheres to a rigorous engineering approach5.
Architecture definition
Architecture is one of the most used (and abused) terms in the areas of software and systems engineering. In order to get a good feel for the complexity of the systems architecture topics, it suffices to list some of the most commonly used architectural categories, methods and models: Enterprise, Data, Application, Systems, Infrastructure, Zachman, Information, Business, Network, Security, Model Driven Architecture (MDA) and certainly the latest silver-bullet: Service-Oriented Architecture (SOA). All of the above architecture types naturally have a whole body of theoretical and practical knowledge associated with them. Any in depth discussion about various architectural categories and approaches is clearly outside the scope of this article; however, it is important to concentrate on the concept of Enterprise Architecture, and the following definition by Philippe Kruchten provide the context for this discussion “Architecture encompasses the set of significant decisions about the system structure”6.
Similarly, Eberhardt Rechtin states7 “A system is defined ... as a set of different elements so connected or related as to perform a unique function not performable by the elements alone”.
In order to emphasize the practical side of architecture development, the two definitions above can be further enriched and a long-time colleague of mine Mike Regan a systems architect with many successful system implementations under his belt adds: “Architecture can be captured as a set of abstractions about the system that provide enough essential information to form the basis for communication, analysis, and decision making.”
From the above definitions, it is clear that system architecture is the fundamental organization of a system. System architecture contains definitions of the main system constituencies, as well as the relationships among these constituencies.
Naturally, the architecture of a complex system is very complex as well. In order to deal with such architectural complexity, some decomposition method is needed. One such method is the Three-Layered Model.
_________________________________
5 It is prudent to concentrate on Enterprise-level architecture since it is the most semantically difficult level and thus has the highest return potential for data quality improvements. All the discussion points below will be also applicable to any lower level concepts: LOB, department, etc.
6 Philippe Kruchten, http://www.kruchten.com/inside/citations/Kruchten2004_DesignDecisions.pdf
7 Systems Architecting: Creating and building complex systems, Eberhardt Rechtin, Prentice-Hall, 1991
Three-Layered Model
All modern architectural approaches are centered on a concept of model layers -- horizontally-oriented groups defined by a common relationship with other layers, usually their immediate neighbors above and below. A possible layering for EA can constitute a capabilities (or business process) layer at the top, the information technology specifications layer in the middle, and the information technology physical implementation layer on the bottom . This model assumes information systems-centered approach; in other words, the purpose of this architectural model is to provide an approach to successful information systems implementation.
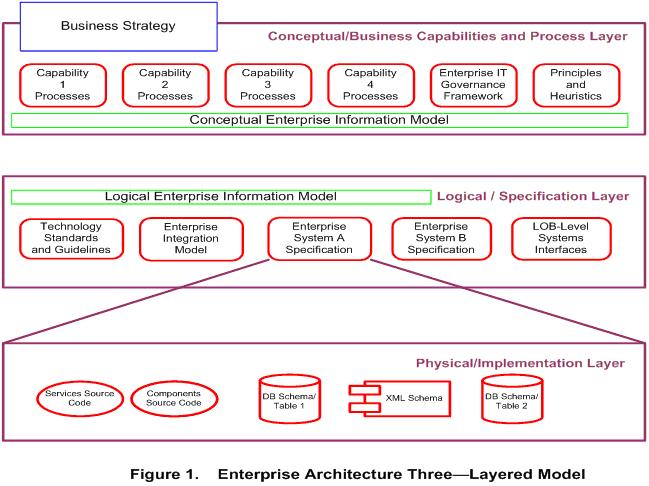
A simplified Three-Layered Model is shown in Figure 1. Some key concepts are worth mentioning:
First, although business strategy is not a constituent of the Business Architecture layer, it represents a set of guidelines for enterprise actions regarding markets, products, business partners and clients. A more elaborate view of these actions is captured by Business Architecture.
Second, the model demonstrates that Enterprise Information Models reside in both the Conceptual as well as in the Logical layers, and provide the foundation for consistent interaction between these layers.
Third, Enterprise IT Governance Framework is defined in the top conceptual layer, while IT standards and guidelines that support the Governance Framework are implemented in the Specification layer.
Finally, Enterprise Specification Layer defines only Enterprise Integration Model for the departmental systems, but not their internal architectures.
The discussion that succeeds the diagram expands on the notion of business process architecture and elaborates on the layering details.
_____________________________________________________
8 This approach is inspired by Martin Fowler’s book “Analysis Patterns: Reusable Object Models”, http://www.martinfowler.com/books.html#ap, as well as by OMG’s Model Driven Architecture (MDA) http://www.omg.org/mda/
Business Architecture
It is important to emphasize the business process layer as the foundation for our Enterprise Architecture model. Carnegie Mellon University (CMU) provides the following definition for Enterprise Architecture: “A means for describing business structures and processes that connect business structures”. Interestingly enough this definition from the CMU Software Architecture Glossary is actually applicable to and definitive of the EA as a whole, and not just for the Business EA.
EA definition used by the US Government agencies and departments emphasizes a strategic set of assets, which defines the business, as well as the information necessary to operate the business, and the technologies necessary to support the business operations.
While this definition maps extremely well to the above proposed three layered view of EA, a word of caution is appropriate: while three layered model provides a good first approximation of Enterprise Architecture, it is by no means complete and/or rigorous. It is obvious that both business and technical constituencies of the EA model can and should be in turn decomposed into multiple sub-layers.
In the quest to make Business Enterprise Architecture (BEA) layer a robust practical concept, BEA has morphed from the initial organizational chart-centered and thus brittle view, into a business process-centered orientation, and lately into business capabilities-centered view, becoming even more resilient to business changes and transformations .
Current consensus around EA accentuates both business and technical constituencies of it. This business and IT partnership is even more highlighted by the advances of the service-oriented architecture (SOA), which views businesses process model and supporting technology model as an assembly of inter-connected services.
__________________________________________________
9 CMU SEI, Software Architecture Glossary, http://www.sei.cmu.edu/architecture/glossary.html
10 http://colab.cim3.net/cgi-bin/wiki.pl?Enterprise_Architecture
The original version is: “Enterprise Architecture ‘‘(A) means—‘‘(i) a strategic information asset base, which defines the mission; ‘‘(ii) the information necessary to perform the mission; ‘‘(iii) the technologies necessary to perform the mission; and ‘‘(iv) the transitional processes for implementing new technologies in response to changing mission needs; and ‘‘(B) includes—‘‘(i) a baseline architecture; ‘‘(ii) a target architecture; and ‘‘(iii) a sequencing plan…”
11 A Business-Oriented Foundation for Service Orientation, Ulrich Homann http://msdn.microsoft.com/architecture/default.aspx?pull=/library/en-us/dnbda/html/ServOrient.asp
Architectural model as a foundation for data quality improvement
Top Business layer
In the proposed three-layered view of the EA, the business process (or capabilities) layer includes a business domain class model . Since this model is implemented at the highest possible level of abstraction, it captures only foundational business entities and their relationships. Thus, the top layer domain model is very stable and is not subject to change unless the most essential underlying business structures change. The information (or data) elements that are defined at this level of the domain model are cross-referenced against the business process model residing in the same top layer. In other words, every domain model element has at least one business process definitions that references it. The reverse is also true: there is no information element called out in the business processes definitions that does not exist in the domain model.
It is also worth pointing out that only common enterprise-level information processes and elements are captured at the top layer of EA. For example, due to historical reasons, an enterprise consists of multiple lines of business (LOB), each carrying out its own unique business process with related information definitions. At the same time, all the LOBs participate in the common enterprise process. In this case, at the top (enterprise level) business process layer, only the common enterprise-level process will be modeled. In extreme cases, this enterprise process will primarily consist of the interfaces between the LOB-level business processes.
Each of the enterprise’s LOBs will need to have its own three-layered model, where top level business entities and the corresponding information (or data) elements will be unambiguously mapped to the enterprise-level model entities. Needless to say, only the elements that have their counterparts at the enterprise level can possibly be mapped. By relating LOB-level definitions to the common enterprise-level equivalents, we are eliminating one of the main reasons for low enterprise data quality: semantic mismatch (a.k.a. ambiguity) between different business units. And since our data elements are cross-referenced with the business process models, we should have enough contextual information to correlate information elements at the enterprise- and LOB- levels. In the most difficult cases, UML State Transition Diagrams should be created to capture temporal and event aspects of the business processes.
Specification layer
The Specification Layer of the three-layered EA model introduces system-related considerations and defines specifications for the enterprise-level information systems. These are the systems that need to be constructed to support the business processes defined at the top layer of the model. By defining system requirements in terms of the business processes, another major cause of low data quality is eliminated: a disconnect between the business and the technology views of the enterprise system.
For example, it is quite common for more than one system to be operating on a data element defined at the top business layer. In this case, each system specification will define its own unique data attribute, but all these attributes are in turn mapped to the one element at the top layer. This top down decomposition approach helps to alleviate a problem known as “departmental information silo”.
Again, similar to the top layer, in the spirit of correlating data with the process contextual information, Business Use Cases Realizations and System Use Cases (or similar artifacts) are introduced at this level to provide enough grounding for the data definitions. It is important to note that in addition to the enterprise systems, the system interfaces of LOB-level systems (to support business process connection points between the different LOBs) are also specified in this layer.
Implementation layer
In this layer, the platform-specific implementation are defined and implemented. Unlike at the Specification layer, multiple platform specific implementations may be mapped to the same element defined at the specification layer. This unambiguous, contextually-based mapping from possibly multiple technology-specific implementations to a data element defined at the technology-independent specification level is the foundation for the robust high quality data management approach.
Conclusion
It is impossible to overestimate the importance of the two-dimensional traceability in the discussed architectural model. The first dimension – vertical traceability between the model layers – provides a foundation for rich contextual connection between the business process and the system implementation that supports this process. The second dimension – horizontal traceability within the same model layer – provides a foundation for a rich contextual connection between the hierarchical organizational units, as well as the systems implemented at their respective levels.
A robust traceability mechanism is absolutely necessary for high data quality to become a reality. The architectural model provides a foundation for the information traceability and thus data quality, without which it is not possible to address a cluster of issues introduced by the modern business environment in general and especially by the legal and regulatory compliance concerns.
posted by semyon axelrod | 7:44 PM
|
0 comments
![]()
![]()